《游戏人工智能编程案例精粹》学习笔记(二)
关于《游戏人工智能编程案例精粹》的学习笔记。本节主要是《掠夺者》的概述,路径规划与目标驱动。
《掠夺者》概述
这是书中的一个案例,基本玩法类似于2d吃鸡。其要求如下:
决策
AI需要制定游戏计划,长期目标,短期目标等。目标可以是攻击敌人、找到血包等。将目标与现有状态进行对比评估,从而作出决策。后面有单独章节介绍这一评估方式。移动
AI需要综合使用上述的移动方式,使移动自然。主要使用的移动方式有Seek,Arrive,Wander,Wall Avoidance 和 Separation。路径规划
AI需要对于一个想要达成的目标,规划合适的路径去达成。后面有单独章节介绍完整的寻路感知
AI需要模拟角色的视觉听觉以及记忆。如果不考虑角色的记忆而只是采用简单的视觉模拟感知,效果将大打折扣。想象一个情况,A的视野中有B,C两个敌人,A选择率先攻击B,于是转向B并发动攻击,这使得C消失在了视野中。于是消灭B后,A便不会回头攻击C,这显然是不合理的。所以可以为AI角色引入记忆功能,例如使用一个map存储上一次遇到各个敌人的时间,根据这个map对较近时候碰到的敌人作出反应。目标选择
AI需要选择合适的目标以发起攻击或追逐等操作,可以简单地以最近的敌人为目标,实际的开发可能需要综合考虑敌人的武器,生命等要素。武器控制
AI需要根据敌人的距离等要素选择合适的武器进行攻击,例如近距离时不使用两败俱伤的爆炸性武器。不同武器也需要不同的瞄准方式,例如瞬发武器可以直接瞄准敌人当前位置,而弹道较慢的武器应当预判敌人的走位。另外,为保护玩家体验,可以加入进入视野到开始射击的反应时间以及射击的精度误差,此处误差建议为0~0.2弧度。武器控制的具体实现采用模糊逻辑。后面有单独章节介绍。tips
- 对于某些游戏,AI对玩家的第一发子弹打偏是一个好主意,这可以提醒玩家AI的出现,使玩家做好准备。同时,如果能看到子弹的轨迹,这也能极大地提高游戏的刺激性
- 当玩家生命值较低时,降低AI射击的精准度。这可以使玩家更频繁地达成死里逃生或绝地反杀,使游戏更加刺激。
路径规划
导航图
为确定一条路径,游戏环境需要被分割为导航图,从而利用搜索算法对导航图进行搜索。常见的导航图有如下几种:
单元
基于正方形或六边形的单元导航图,每个图中的节点表示一个单元,图中的边表示相邻单元的连接。对于类似文明的游戏,每个单元通过的消耗不一,这可以为每个地图分配相应的地图信息,使用该信息为地图的边加权。
这一方法的问题在于随着单元格的增加,导航图的节点和边也将急速增加。可视点
也即POV导航图,通常手工放置地图中的关键点并将它们连接起来。作为游戏中的导航图。
如果地图较为庞大复杂导致手工填充地图过于耗时,或是有随机生成地图功能,就需要开发自动生成POV图的方法,例如下面的扩展图形。扩展图形
如果游戏环境由多边形构建,可以利用图形自带的信息去创建POV图。- 将多边形向外扩展一定的半径(略大于智能体半径)
- 把扩展出的图形的顶点作为导航图的节点
- 测试这些节点的可见性,得出导航图
因为扩展了一定的半径,智能体便可以沿导航图自由通行而不撞到墙壁。
导航网
也即NavMesh,使用凸多边形描述游戏环境中的可访问区域。这里利用了凸多边形的重要性质:凸多边形的任意顶点可以互相直线到达。图的每个节点代表一个凸多边形区域而非一个点。
粒度
粗粒度
导航图较为简单,且只能沿导航图的边移动。类似吃豆人的游戏可以采取这种策略,但是需要任意导航的RTS游戏不适用。细粒度
增加导航图的粒度。细粒度导航图的生成通常使用洪水填充算法。- 将一个种子节点放入地图中
- 算法在每个节点的方向上向外扩展纳入图中
- 重复以上步骤,直到所有可以通航的区域都被填充满
路径平滑
当游戏导航图是网状而实际游戏地图可以任意导航时,自动寻路创建的路径通常有额外的边。例如如下情况。
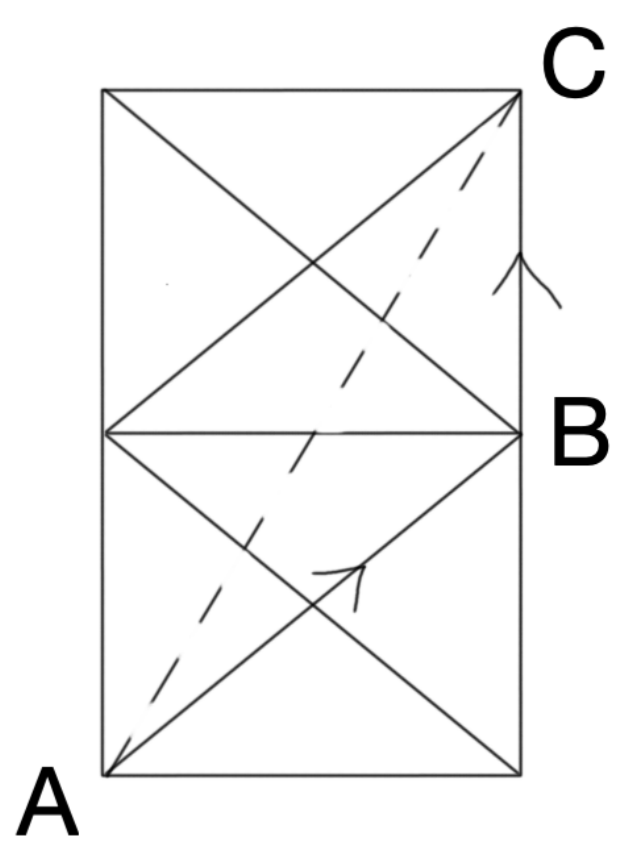
A点试图到达C点,由于图的拓扑限制了45度的转向增量,寻路的结果可能是由A到B到C,但是实际游戏中需要从A到C直线前进,这时就需要对路径进行平滑处理。
粗糙而快地平滑路径
算法按如下步骤执行- 将两个迭代指针E1和E2放在第一条边和第二条边上。
- 如果E1的起点和E2的终点之间可直达(注意考虑智能体体积),说明E1和E2可被省略。在这两点之间连接一条新边,作为E1,将下一条边作为E2。
- 如果无法直达,则把E2赋给E1,并将E2指向路径中的下一条边。
- 重复以上步骤,直到E2的终点等于路径目的地。
精确而慢地平滑路径
每次E1向前移动,必须遍历从E1到最后一条边之间的所有边。这种方案较为精确但是显然消耗巨大。
降低消耗
预先计算好的路径
地图创建的同时,为地图创建一份查询表,查询表中包含每个节点到图中任意节点的路线。这可以用Dijkstra算法为每个节点创建一个最短路径树(SPT)以实现,并将SPT直接存储在一个二维整数数组中。
查询表存储在二维整数数组的一个方式示例:
节点0到节点5的最短路径的下一个节点是节点3,则将3存储在SPT[0][5]中,以此类推。预先计算成本
当考虑游戏中智能体的决策时,有时需要计算成本,例如移动所需的时间。如果对于每次决策都需要计算所有成本,那消耗将十分巨大。这时就需要一个计算好的成本表,这一创建方式与路径表类似,不过改为存储最短路径的总时间成本。分层路径寻找
利用两个不同粒度的导航图存储整个地图,例如对于中国地图,可以用粗粒度的导航图存储省之间的连接信息,细粒度的导航图存储城镇或道路的连接信息。当然如果两层不足以保证质量,也可以使用更多层。
![分层路径寻找]()
走出困境
当一个环境中包含大量智能体时,智能体将很容易陷入困境,例如在狭窄的门附近拥堵。例如在一个狭窄的门口,某一智能体试图定位附近的一个路点作为目标。这时由于某些原因,智能体被挤出了门,而智能体仍然在试图向该路点直线移动。这时该智能体就会开始日墙。
解决方案是每当更新时,计算到当前路点的距离。如果这个值的变化超过了预期,就需要重新规划路径。
目标驱动智能体行为
游戏中智能体的游戏思路事实上可以分解为多个目标,而目标也可以分为更细。例如对于掠夺者游戏,角色为了赢得游戏,可以先去搜集武器;为了搜集武器,需要寻找武器的位置并获取武器;而如果在寻找武器的途中突然遇到了敌人,就需要评估双方实力并转而攻击敌人或者逃跑;攻击敌人的过程中需要选择合适的武器攻击敌人并不断走位;如果选择了攻击敌人并成功消灭敌人后,还需要继续刚才的寻找武器行为。
- 目标的实现类似于状态,不过分为更多层次。分解和试图达成目标的行为不断进行,直到整个层次已被遍历。目标具有类似状态模式中Enter,Execate,Exit的Activate,Process,Terminate方法。不同的是Activate可能需要每当激活该目标时被调用以进行初始化。
- 层次目标的实现类似于组合模式。同时通过将子目标压入子目标容器的前面以添加子目标,按照LIFO的顺序进行处理。
- 目标之间的选择使用目标仲裁,通过整体目标Think实现,需要对当前的状态进行评估以计算不同目标的价值分数,比较得到合适的目标。
- 为实现自动恢复被中断的活动,例如击杀半路遇到的敌人后继续寻找武器这一功能,其整体实现原理需类似于下推自动机。如果出现击杀敌人后寻路起点变化导致寻路丢失,也会因寻路目标的Activate再次被调用而重新开始寻路。
- 游戏中可能需要一些特殊的障碍,例如打开开关才能开启的门。这些障碍应该存储在地图的信息中作为对AI透明的数据,需要花费的时间也应该体现在导航图的边成本中。为了使AI存储这些障碍,特殊的边需要额外存储对应的开关,当智能体试图通过该边时,通过备注的开关信息将开启开关这一新目标压入栈中
命令综述
在掠夺者案例中,有如下一些组合命令举例
- Think
也即游戏中的整体目标 - GetItem
控制角色寻找回血道具/武器等,这与玩家的生命/距离目标的距离等相关。如果需要让角色在离物品较近时更倾向于获取物品,可以使评分与距离的平方成反比。 - MoveToPosition
试图将角色移动到地图上的任意位置,这会请求一条路径。如果利用时间片方式进行规划,在路径被规划完成前,角色可以随机漫步。 - AttackTarget
当玩家认为自己能够战胜当前目标敌人时,便可以主动攻击敌人。这包含了复杂的逻辑,例如选择合适的武器,进行走位以躲避子弹并达到武器最佳攻击距离等等。角色攻击目标的评分可以取决于当前双方的生命值/距离/武器等因素 - HuntTarget
当AttackTarget行为的目标消失在视线中时,角色可能需要继续追击敌人。这需要再次评估且评分应当低于攻击视线中的同样敌人,毕竟追击敌人需要承担更多的未知风险。
和如下基本命令举例
- Wander
控制角色随机漫步 - TraverseEdge
控制角色沿着一条路径移动,这可能需要使用上一节提供的各种技巧。
其他优化策略
- 使AI可以在一定程度上预判其他角色(例如玩家)的行为。例如当玩家残血时,AI控制角色移动到较近的血包附近埋伏玩家。这可以通过对玩家的当前状态调用AI的目标评估函数得知角色的大致行为,这种预判的准确性取决于你设计的AI评估函数是否贴近玩家心理。
- 使游戏中的AI具有不同个性。对于每种目标的评估函数,可以增加一个因子,作为角色的个性。例如在一个RTS游戏中,AI可以有运营风格,速攻风格等等;在掠夺者游戏中,AI可以有武器选择偏好,射击精度等等。
- 不同于FSM,目标仲裁事实上是一个数据驱动而非逻辑驱动的算法,所以只需改变数据就能改变AI角色的个性与行为,也可以将数据单独存放在脚本文件或一个表中使其便于调试。