《Game AI Pro》寻路算法的优化
关于《Game AI Pro》 Pathfinding Architecture Optimizations和 Choosing a Search Space Representation的学习笔记,主要涉及$\mathrm{A*}$算法的一些优化以及搜索空间表示的选择,需要读者对$\mathrm{A*}$算法有基本的了解。(之前的章节懒得补博客了
使用查找表构造高质量的启发因子
我们可以使用$Floyd$算法预先得到一个查找表,将它压缩后在实时运算中作为 $\mathrm{A*}$ 算法的启发因子。毕竟不压缩就不需要 $\mathrm{A*}$ 了
这里压缩的方法在2012年的GPPC(Grid-Based Path Planning competition,基于网格地图寻路的比赛,JPS跳点算法也在其中被提出)中被提出。当然这一压缩方法也不仅适用于网格地图。
在一个地图中,会有许多关键的节点,在FLoyd算法的查找表中,到这些节点的路径会被反复计算,这些点被称为枢纽,对于每个点z,在查找表中只记录到枢纽的距离d(p,z),当我们需要两个点间的估计距离作为启发因子时,令 $h(x, y) = |d(p, x) – d(p, y)|$即可。如果我们选择了多个枢纽,就选取以每个枢纽计算得到的估计距离中的最大值。这一方法被称为欧氏嵌入 (Euclidean embedding),兼顾了空间与时间。
接下来的问题则是枢纽的选择,这因游戏类型而异。例如,在一个RTS游戏中,可以选取双方的基地为枢纽;在一个RPG游戏中,则可以选择地图的出入口和主城为枢纽。
更好的搜索空间表示
常见的三种表示是基于方格(grid)、路点(waypoint)、导航网格(navmesh)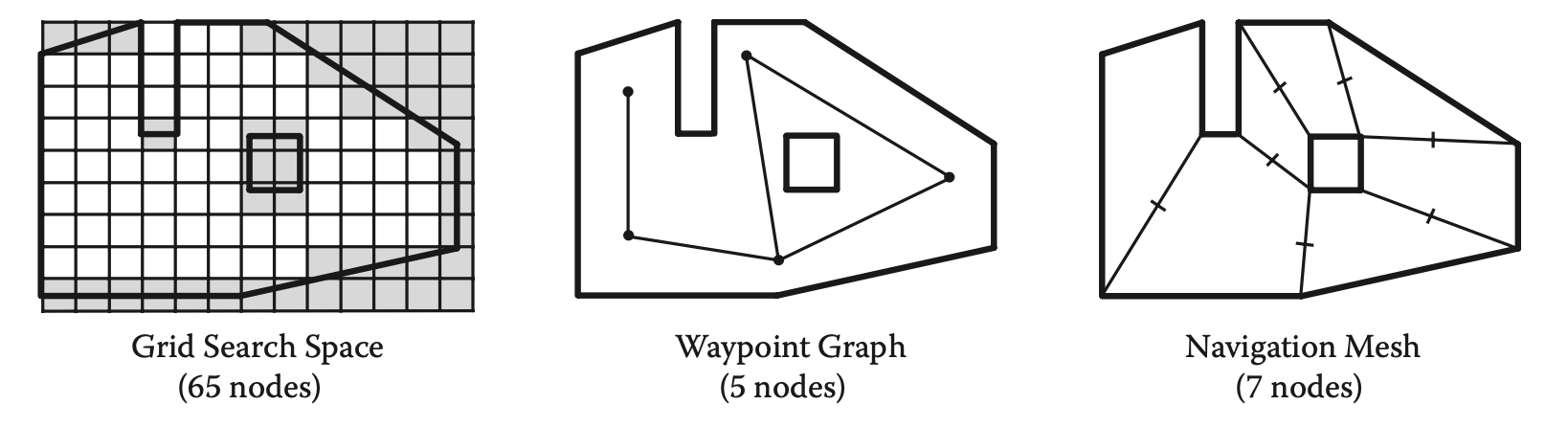
其思路不再赘述,以下为几种搜索空间表示的优劣对比。
Grid
- 优点
- 简单,易于实现
- 对地图编辑器友好
- 特定方格的消耗/可通行性易于修改,当然重新加权的方格太多也会影响速度
- 从游戏地图位置容易映射到方格位置,坐标除以每个网格的边长即可
- 缺点
- 对于大型地图,方格属于内存密集型
- 通常需要对所得的路径进行路径平滑
- 由于粒度过细,路径规划的消耗可能较大
- 通常含有许多对称路径,增加了路径规划的成本。这一问题可以通过一些技术缓解
Waypoint
- 优点
- 同样易于实现
- 如果能够提前预知改动(例如一扇门的开关),则同样易于修改
- 稀疏的表示使得存储和路径规划的消耗都较低
- 缺点
- 如果边过少,路径质量会受到影响;过多则会影响存储与路径规划的复杂度
- 需要手动放置节点才能得到较好的路径质量
- 玩家的位置映射到路点图的数据结构(localization)较为困难,玩家被碰撞出边时可能难以定位
- 未储存明确的物理等底层状态空间表示信息,平滑路径时可能会导致角色卡在物理对象上
- 如果改动无法被预知,修改的过程较为复杂,需要验证附近的所有路点是否因为地形修改导致可被连接。(例如角色可以任意地进行墙体破坏)
Navmesh
- 优点
- 多边形可以比网格更精确地表示游戏世界,因为它可以处理非网格对齐的地图
- 多边形精确表示有利于路径的平滑
- 路径规划非常快且不影响质量
- 不像网格一样消耗内存
- 缺点
- 实现过于复杂,不过有非常不错的开源实现
- 需要使用特殊的几何算法,在某些特殊情况(如平行线)可能导致失败。这更增加了实现的难度
- 对导航网格的改动可能难以实现且消耗较大
- 如果实现不好,localization可能比较复杂。优秀的实现可能会借助额外的数据结构,如gird进行映射
总结
每种路径规划架构都有自己的优点和缺点。架构的选择应该取决于正在开发的游戏类型、已有的工具以及可用于实现和调试的时间。许多游戏引擎都自带路径规划表示,但对于必须进行新的实现的情况,其优缺点总结如下。
当地形是2D时,当实现时间有限,当世界是动态时,当内存充足时,网格是最有用的。它们并不适合大型的开放世界游戏,或者需要高质量动画的可行走空间的精确边界的游戏。
当实现时间有限,需要快速路径规划,以及不需要世界的精确表示时,路点图是最有用的。当有足够的时间进行测试和实现时,导航网格是最好的。如果实现得好,导航网格是最灵活的实现方式,但对于小项目来说,导航网格可能是矫枉过正。
但是在大型游戏中,简单地使用这些表示方式可能并不能解决问题。常用的方法是分层寻路,例如在不需要精细寻路的高层次中采用路点或导航网格描述,低层次中使用方格。当存储空间不足以使用上述的$Floyd$查找表时便可以采取这一思路。其在英雄连、龙腾世纪:起源等游戏中被采用。
预分配所有重要的存储空间
在搜索过程中分配存储空间会导致效率数量级级别的下降。所以应当使用内存池预分配搜索所需的空间。
高估启发因子
$\mathrm{A*}$作为具有可采纳性(admissible) 的寻路算法,其对于当前节点到目标的距离估算需不高于实际的距离。不过在实际项目中,你可以通过适当地高估启发因子舍弃部分可采纳性以换取巨大的速度提升。在传统寻路领域中,这听起来简直离经叛道,但在电子游戏领域,这是一种可行的权衡。
为了理解具体的高估方式,我们来看传统的$\mathrm{A*}$开销计算函数
\begin{equation}
f(x)=g(x)+h(x)
\end{equation}
对启发因子进行加权后形式如下
\begin{equation}
f(x)=g(x)+h(x)\times weight
\end{equation}
通过调整权重$weight$,即可得到不同的$\mathrm{A*}$形式。如果权重为0,退化为$Dijkstra$算法,开销估计仅由之前的累计消耗决定。如果权重为1,即为经典的$\mathrm{A*}$算法。如果权重大于1,则算法向贪婪最佳优先算法(Greedy Best-First search)靠近。
在实际操作中,我们可以将权重在1.1到1.5之间调整,这取决于你的地图形式。如果你的地图较为复杂,充斥着随机障碍与回溯,这种方法对可采纳性的破坏则较为严重;如果你的地图较为简单,增大权重将极大地增加寻路算法靠近终点的速度。虽然这一方法有一定风险,也不失为值得探索的思路。
更好的启发因子
对于一个能8方向移动的方格地图而言,常见的启发因子有以下三种
- 欧氏距离 Euclidean distance 通常会低估实际消耗
- 曼哈顿距离 Manhattan distance 通常会高估实际消耗
- 八分距离 octile distance 对于此类地图是较优的启发因子,允许45度和90度的转弯,计算方式为$max(Δx, Δy) + 0.41 · min(Δx, Δy)$
开放队列排序
- 常见的存储开放队列的方式是堆,但是由于新加入的节点经常被立刻删除,可以在删除前先缓存新节点。
- 还可以避免显式排序。在某些地图中,独一无二的f会比较少,这种情况可以改为维护f的列表而非节点的列表
- 在一些搜索中,开放列表中只有10到30个节点,这时直接使用数组存储开放列表可能较为简单
避免寻路中的回溯
即使是最简单的剔除(例如剔除已经经过的节点)也能极大地加快寻路的速度。更为高级的剔除则衍生出了$\mathrm{A*}$的许多变种,例如前文提到的JPS跳点算法
缓存后继任务
$\mathrm{A*}$算法需要频繁地考察相邻的节点,故直接将相邻节点存储起来而非在复杂的数据结构中遍历也能提高速度,当然这会导致更大的空间消耗。
寻路中的坏主意
同时搜索
尽量避免同时开始多次搜索。因为$\mathrm{A*}$算法需要开辟较大的空间,同时进行多个搜索会导致极大的空间消耗。如果我们发现搜索的速度确实差距较大,可以分两个通道分别处理一般的寻路和较慢的寻路。
双向寻路
一般而言,当有大陆-岛屿存在时,双向寻路可以通过快速遍历岛屿上的节点迅速判断出发点和目标之间的不可达关系,而$\mathrm{A*}$需要遍历大陆中的节点得出同样的结论。但这并非使用双向寻路的理由,解决这个问题可以通过分层寻路,在宏观上先判断可达性,再使用$\mathrm{A*}$得到具体路径。
当然,抛开岛屿问题,双向寻路对于$\mathrm{A*}$也徒劳无功。所以,不要在$\mathrm{A*}$中使用双向寻路。
缓存失败的寻路结果
在某些算法中,缓存中间结果可以减少重复计算,但在$\mathrm{A*}$中并不适用,因为有太多不同的路径,存储中间结果对于空间的消耗过大。
结语
以上即为一些常用的$\mathrm{A*}$算法优化方式,希望能给读者一些启发。